Digital Experiment Platform
Faster, smarter insights
Faster, smarter insights
from R&D experiments.
The Synthace digital experiment platform lets you design powerful experiments, run them in your lab, then automatically build structured data. No code necessary.
Request a Demo Show me how




State of the industry 2024
Trouble with automation and experimental insights
Struggling to make go/no-go decisions based on your experiment data? Having trouble automating experiments and fully utilizing lab equipment? Turns out you're not alone.
We surveyed a total of 250 scientists and decision makers working in life science R&D to understand their challenges.
GET THE REPORT
Run experiments that were previously impossible
High throughput DOE automation and data isn't a pipe dream, it's already here. Unleash your equipment to work full pelt on the hardest problems you need to solve today, tomorrow, and every other day after that.

Slash time to insight with dynamic automation
Run V1 in the morning… then V2 after lunch. With Synthace's dynamic automation, you can update your experiments as often as you like, without (re)writing code: run your experiments this way, then that way, then back again. Act on your decisions with lightning speed.
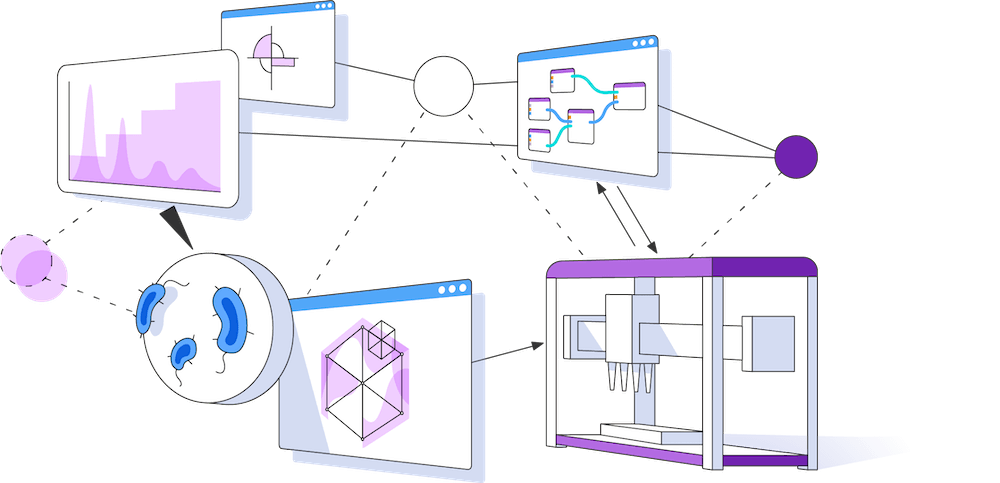
Enjoy context rich experiment data
Automatically gather and structure your experiment designs, experimental data, and metadata, all in one platform. Visualize and analyze results in the context of the experiment as you designed it and as it really ran.
Build on your results with protocol reproducibility
Synthace runs the same no matter the lab, machine, or team. Digital experiments capture and control for the true intent of your experiments, no matter the context you run them in.
“Using Synthace and DOE has changed the way we do experiments, but more interestingly the way we think and communicate.”
“Synthace platform reduces barriers for researchers to use lab equipment and generate more quality data in a short time. This allows for more complex experimentation with dramatically reduced possibility for human error.”
“We can develop protocols much faster with Synthace. We’ve reduced timeframes from a couple of weeks to usually less than a week for more complex processes.”
“Synthace allows us to make it routine for us to walk away from creating 24-48 constructs so our scientists can focus on other tasks”
“Synthace allows us to think outside the box, and do things we couldn't do before.”
“Synthace is an easy, visual and unique way to design workflows and analyze data. Combined with attentive customer service, it helps me realize the experiments I want to accomplish.”
“In just a few months, Synthace saved me from performing 20,000 manual calculations—it’s all done for me.”
Why biology needs digital experiments
Digital experiments are a powerful, unified blueprint. They're a shared model, and a way to run experiments that we used to think were impossible.
Read the blog